std::async verhält sich wie ein asynchroner Funktionsaufruf. Unter der Haube ist std:.async eine Task, die sich sehr leicht verwenden lässt.
std::async
std::async nimmt als Arbeitspaket eine ausführbare Einheit an. Dies ist in dem konkreten Beispiel eine Funktion, ein Funktionsobjekt und eine Lambda-Funktion.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
#include <future> #include <iostream> #include <string> std::string helloFunction(const std::string& s){ return "Hello C++11 from " + s + "."; } class HelloFunctionObject{ public: std::string operator()(const std::string& s) const { return "Hello C++11 from " + s + "."; } }; int main(){ std::cout << std::endl; // future with function auto futureFunction= std::async(helloFunction,"function"); // future with function object HelloFunctionObject helloFunctionObject; auto futureFunctionObject= std::async(helloFunctionObject,"function object"); // future with lambda function auto futureLambda= std::async([](const std::string& s ){return "Hello C++11 from " + s + ".";},"lambda function"); std::cout << futureFunction.get() << "\n" << futureFunctionObject.get() << "\n" << futureLambda.get() << std::endl; std::cout << std::endl; } |
Das Programm und seine Ausgabe birgt nicht viel Überraschungspotential.
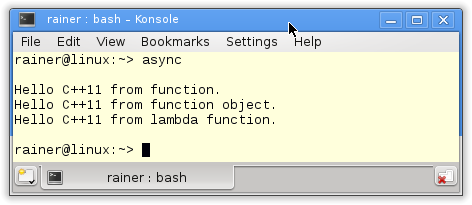
In Zeile 21 wird der Future mit einer Funktion, in Zeile 25 mit einem Funktionsobjekt und in Zeile 28 direkt mit einer Lambda-Funktion parametrisiert. Zum Abschluss fordern alle Futures ihren Wert (Zeile 30) an.
Es geht auch ein bißchen formaler. Die std::async Aufrufe in den Zeilen 21, 25 und 25 erzeugen einen Datenkanal zwischen den zwei Endpunkten Future und Promise. Das Arbeitspaket des Promise sind die bereits zitierten aufrufbaren Einheiten. Durch die get-Aufrufe in Zeile 30 fordern die Future das Ergebnis ihrer Arbeitspakete an. Sobald der Promise sein Arbeitspaket erhält, beginnt er sofort damit, seine Arbeit zu verrichten. Dies ist aber nur das Defaultverhalten.
Eager oder Lazy Evaluation
Eager (gierig) oder Lazy (faul) Evaluation bezeichnet in der Programmierung zwei verschiedene Strategien, das Ergebnis eines Ausdrucks zu berechnen. Während bei der Eager Evaluation der Ausdruck sofort berechnet wird, wird bei der Lazy Evaluation das Ergebnis eines Ausdruckes erst dann berechnet, wenn es benötigt wird. Gerne wird die Lazy Evaluation als Bedarfsauswertung bezeichnet. Lazy Evaluation oder auch Bedarfsauswertung spart Zeit- und Rechenpower, denn es gibt kein Rechnen auf Verdacht. Ein Ausdruck kann eine mathematische Berechnung, ein Funktions- oder ein std::async-Aufruf sein.
Per Default berechnet std::async sein Ergebnis sofort. Das C++-Laufzeit entscheidet, ob dies im gleichen oder einem neuen Thread geschieht. Mit dem Flag std::launch::async kann std::async explizit dazu aufgefordert werden, einen neuen Thread zu starten. Im Gegensatz dazu schreibt das Flag std::launch::deferred der C++-Laufzeit vor, den std::async-Aufruf im gleichen Thread auszuführen. Die Ausführung ist in diesem Fall lazy. Das heißt insbesondere, während bei der Eager Evaluation std::async sofort mit der Ausführung seines Arbeitspaketes beginnt, stößt bei der Lazy Evaluation mit std::launch::deferred der get-Aufruf des Futures die Arbeit erst an.
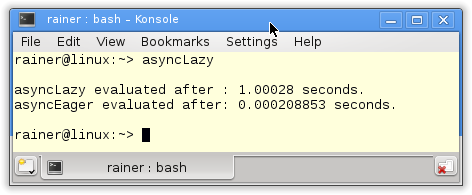
Die Eager und Lazy Evaluation lässt sich schön an dem Programm nachvollziehen.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
#include <chrono> #include <future> #include <iostream> int main(){ std::cout << std::endl; auto begin= std::chrono::system_clock::now(); auto asyncLazy=std::async(std::launch::deferred,[]{ return std::chrono::system_clock::now();}); auto asyncEager=std::async( std::launch::async,[]{ return std::chrono::system_clock::now();}); std::this_thread::sleep_for(std::chrono::seconds(1)); auto lazyStart= asyncLazy.get() - begin; auto eagerStart= asyncEager.get() - begin; auto lazyDuration= std::chrono::duration<double>(lazyStart).count(); auto eagerDuration= std::chrono::duration<double>(eagerStart).count(); std::cout << "asyncLazy evaluated after : " << lazyDuration << " seconds." << std::endl; std::cout << "asyncEager evaluated after: " << eagerDuration << " seconds." << std::endl; std::cout << std::endl; } |
Beide std::async-Aufrufe in Zeile 11 und 13 geben als Ergebnis den aktuellen Zeitpunkt zurück. Während der erste Aufruf faul ist, ist der zweite gierig. Das bringt das kurze Schlafen von einer Sekunde in Zeile 15 auf den Punkt. Durch den asyncLazy.get()-Aufruf in Zeile 17 wird das Ergebnis der Berechnung erst nach einer Sekunde schlafen angefordert. Hingegen holt der asyncEager.get()-Aufruf das bereits vorhandene Ergebnis ab.
Größere Rechenaufgaben
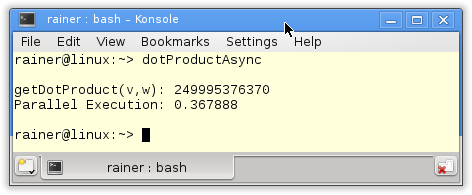
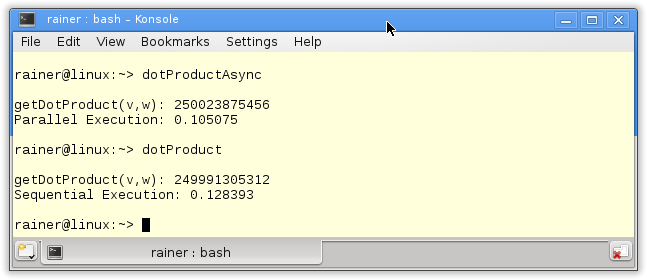
Natürlich bietet es sich an, mit std::async größere Rechenaufgaben auf mehrere Schultern zu verteilen. So wird in dem Programm die Berechnung des Skalarprodukts auf vier asynchrone Funktionsaufrufe verteilt.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 |
#include <chrono> #include <iostream> #include <future> #include <random> #include <vector> #include <numeric> static const int NUM= 100000000; long long getDotProduct(std::vector<int>& v, std::vector<int>& w){ auto future1= std::async([&]{return std::inner_product(&v[0],&v[v.size()/4],&w[0],0LL);}); auto future2= std::async([&]{return std::inner_product(&v[v.size()/4],&v[v.size()/2],&w[v.size()/4],0LL);}); auto future3= std::async([&]{return std::inner_product(&v[v.size()/2],&v[v.size()*3/4],&w[v.size()/2],0LL);}); auto future4= std::async([&]{return std::inner_product(&v[v.size()*3/4],&v[v.size()],&w[v.size()*3/4],0LL);}); return future1.get() + future2.get() + future3.get() + future4.get(); } int main(){ std::cout << std::endl; // get NUM random numbers from 0 .. 100 std::random_device seed; // generator std::mt19937 engine(seed()); // distribution std::uniform_int_distribution<int> dist(0,100); // fill the vectors std::vector<int> v, w; v.reserve(NUM); w.reserve(NUM); for (int i=0; i< NUM; ++i){ v.push_back(dist(engine)); w.push_back(dist(engine)); } // measure the execution time std::chrono::system_clock::time_point start = std::chrono::system_clock::now(); std::cout << "getDotProduct(v,w): " << getDotProduct(v,w) << std::endl; std::chrono::duration<double> dur = std::chrono::system_clock::now() - start; std::cout << "Parallel Execution: "<< dur.count() << std::endl; std::cout << std::endl; } |
Das Programm greift auf die Funktionalität der Zufallszahlen- und Zeitbibliothek zurück. Diese beiden Bibliotheken sind Bestandteil von C++11. In den Zeilen 25 - 41 werden die zwei Vektoren v und w erzeugt, in der for-Schleife (Zeile 38 - 41) erhalten sie jeweils hundert Millionen (100000000) Elemente. Diese Elemente erzeugt die dist(engine) (Zeile 39 und 40) gleichverteilt auf dem Bereich 0 bis 100. Die eigentliche Berechnung findet in der Funktion getDotProduct (Zeile 10 -18) statt. In ihr wird das Skalarprodukt der zwei Vektoren berechnet. Dabei kommen vier std::async-Aufrufe zu Einsatz, die intern den Standard Template Library Algorithmus std::inner_product verwendet. Die return-Anweisung sammelt die Ergebnisse mit Hilfe der Futures ein.
Auf meinem PC mit vier Kernen benötigt die Berechnung des Skalarproduktes ca. 0.4 Sekunden.
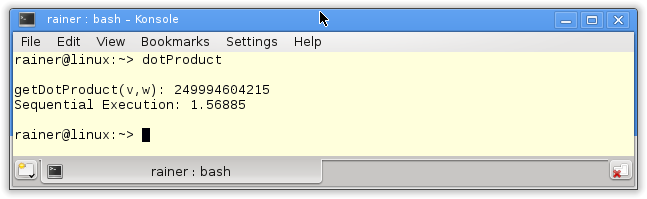
Das stellt sich natürlich die Frage. Wie ist die Performanz, wenn das Skalarprodukt auf einem Kern ausgerechnet wird? Eine leichte Modifikation der getDotProduct Funktion bringt es ans Licht.
long long getDotProduct(std::vector<int>& v,std::vector<int>& w){ return std::inner_product(v.begin(),v.end(),w.begin(),0LL); }
Die Ausführung des Programms is ca. um den Faktor 4 langsamer.
Optimierung
Wird das Programm mit der höchsten Optimierungsstufe O3 auf dem gcc übersetzt, relativieren sich Performanzunterschiede deutlich. Die parallele Ausführung ist ca. um 10 Prozent schneller.
Hintergrundinformation
- Eager und Lazy Evaluation
- In dem Linux-Magazin-Online Artikel gehe ich auf die Grundzüge der funktionalen Programmierung und auch explizit auf Bedarfsauswertung ein.
-
Wie geht's weiter?
Weiter geht es im nächsten Artikel mit dem Parallelisieren von großen Rechenaufgaben. In diesem Fall mit dem Task std::packaged_task.
-
 Go to Leanpub/cpplibrary "What every professional C++ programmer should know about the C++ standard library". Hole dir dein E-Book. Unterstütze meinen Blog.
Go to Leanpub/cpplibrary "What every professional C++ programmer should know about the C++ standard library". Hole dir dein E-Book. Unterstütze meinen Blog.






Weiterlesen...